|
Faults /
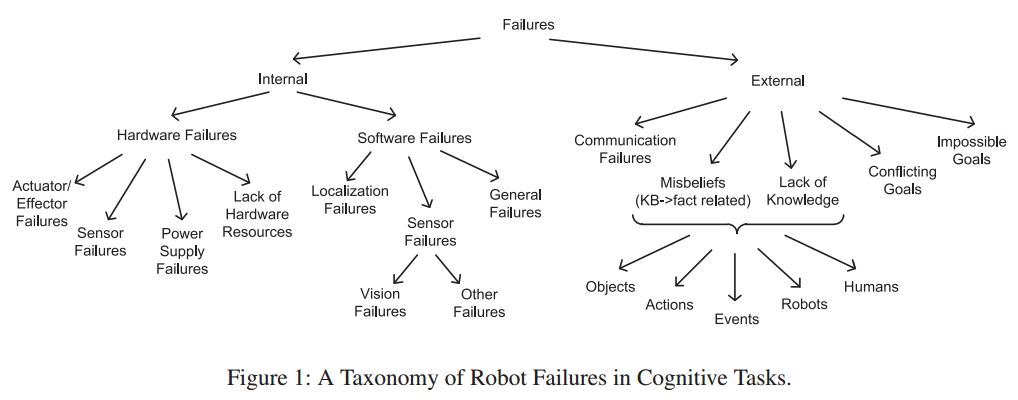
TaxonomyOverviewThe types of faults that robots must be able to deal with is extensive: the faults one would expect with any software and hardware system, with the additional faults possible from the added requirement that a robot must interact with its environment. One effective way to categorize these faults is show below, with the first distinction being between that of faults internal to the robot and those which are a result of external factors. This gives a good snapshot of what can go wrong. These failures all exist at a fairly high level of abstraction. For example, a "General Failure" in software may be the result of any number of lower level faults, such as a race condition or an array out of bounds exception. See below for the types of low level faults I am currently investigating. It is important to note that not only to robots have to deal with a novel set of faults, the impact of generic types of faults can have a much more devastating impact. Robots must be able to be resilient to faults, otherwise the number of applications for which they can be used safely will be greatly reduced. So it is with renewed vigor that we must investigate all possible classes of errors and their possible solutions. Software faultsDeterministic software faults are well understood and there are strategies to prevent and mitigate them. For these faults, however, the techniques examined in Detection and Recovery often will not work. For example, if a software component fails on a specific input due to a programming error, having three copies of that component all failing at once is not particularly helpful. One expensive strategy for preventing these faults is the work with formal verification done in seL4. Instead, the work focuses on hardware faults (described below), but may allow for some extension into intermittent software faults. Intermittent software faults are often a result of multithreaded environments in which there is some shared state. For example, a component with multiple threads may occasional freeze due to a rare race condition. There is no direct correlation between the inputs to the system and the fault, and the solution is to restart the component (or fix the bug). Transient Hardware FaultsThree general categories for hardware faults:
Generally, faults that are difficult to replicate, such as sporadic interference and cosmic rays. These are the main faults which I intend to investigate. A Single Even Upset (SEU) is the term for when some form of radiation interacts with a hardware component and causes a change in state. This is manifested as a "flipped bit." Extremely rare, but less so as component sizes shrink (more susceptible) and increase in number (larger target area). Unless buried in a concrete bunker (in which case Neutrinos would still be a (very rare) risk), systems will need mechanisms to protect from SEUs. There are existing strategies to deal with errors in computer memory (Error Correcting Codes) and in communication channels (Error Detection and Correction). These techniques were developed to handle a variety of problems, and fortuitously SEUs also happened to be largely protected from by them. This leaves the problem of redundancy in computations, which is still an active area of research. This is discussed in the fault detection section. By EffectsYet another way to classify faults in a system is by the observable effects on execution. This is the method used in the Shye work, which provides process level redundancy. This particular work is focused on Single Even Upsets. With this methodology, there are three main categories:
OtherThe classification of faults presented here is not complete, and is likely in need of revision. I will likely need to investigate Permanent Hardware faults. Another thing to keep in mind is if the domain of robotics has any impact on the techniques I investigate. Glossary / Acronyms
|