|
Faults /
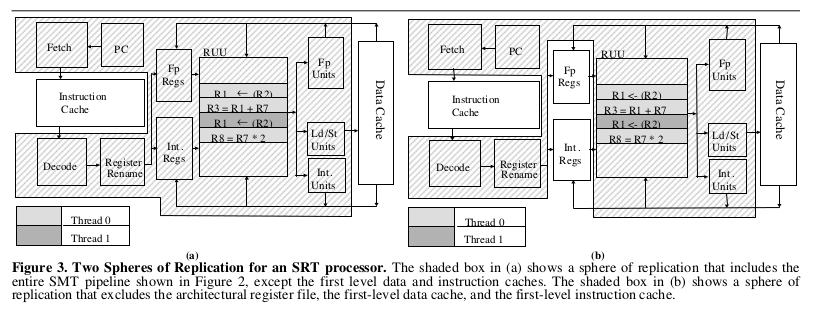
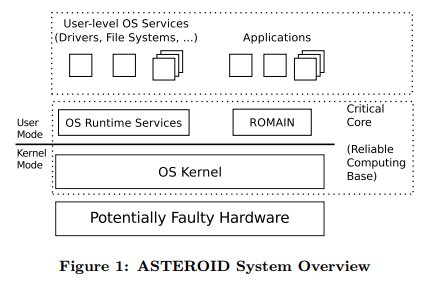
DetectionSpecifically, detection of SEUs that effect the CPU. Connections / buses and memory are ignored, as there are well understood techniques to deal with these components such as (Todo: look into common techniques, forward error correction, error correcting codes, etc.)... The technique used to detect faults will impact the possible Recovery mechanisms. Approaches can be roughly divide by how much custom hardware is required to implement the scheme. This is sometimes phrased as spacial redundancy verse temporal redundancy. The assumption is that the program must be run twice, whether it is on the same hardware at different times or at the same time on different hardware. Note: this is improved upon by the later Reinhardt / Mukherjee work, in which redundant threads are tagged to run on different computational units, which opens the possibility to detect permanent hardware errors. Note: the SlicK work violates this by running a main thread and using predictors to check for discrepancies, which lessens overhead at the cost of no longer being able to insure 100% coverage. DeterminismA key to understanding this work is to understanding the role which determinism plays in it. First of all, the way in which these faults are defined can be couched in terms of determinism: faults which do not display deterministic behavior. It is this definition by which the faults are detected. Some segment of code is executed redundantly, and the central assumption is that it is deterministic: giving the same inputs the redundant executions should have identical outputs. So when examining this work we must be wary of possible violations of this assumption. An instruction level granularity (as one sees with lockstep processors) fulfills this requirement trivially. The Reinhardt / Mukherjee work defines a sphere of replication which can help ensure that determinism is maintained... TODO: elaborate and give an example. The Fiasco.OC work itself defines a sphere of influence, although not explicitly. (TODO: RCB... Syscalls and Exceptions) Additionally, in discussing a possible expansion to allowing multithreading, they acknowledge that the multithreading model would have to be deterministic (TODO: Maybe a link to a referenced paper about deterministic multithreading). It would be useful to keep in mind the ways in which non-determinism may enter a system. For example, shared memory, interrupts, exceptions, and multiple threads are examples of possible sources of non-determinism. Depending on the SoR, other sources may become relevant. For example, some caches have random replacement schemes (I believe the Beagle Bone Black may... this was a source of trouble in some previous work done with an L4 variant if I recall correctly). This would be problematic if the boundary of your SoR was defined in part by cache misses. Duplicate HardwareAn earlier commercial solution was to provide two identical processors which run in lockstep together. Upon the completion of every instruction, the results are compared to see if an error occurred. My interest in this solution is limited as it is costly; in both performance measures and hardware costs. At best the system will run at the same speed (assuming no check overhead) with twice the amount of hardware. SAFER is an architecture that can be configured and / or expanded to detect errors. The common case is for SAFER to recover from errors via standbys with the assumption of fail stop. However, it two processes are running (primary and hot-standby) are being used, then results could be compared to detect an SEU. With three voting could select the correct output. Small Hardware ModificationsSimultaneous and Redundantly ThreadedThis is the redundant multithreading technique developed by Reinhardt and Mukherjee in this 2000 . That paper cites two other similar attempts: Rotenberg's AR-SMT and Austin's DIVA (although DIVA runs on a simpler, dedicated processor). These attempts are all steps away from the commercial attempts at the time which had two identical processors (or cores?) running in lockstep. Parashar expanded upon this idea in a paper which inspected "slices" of computation, only re-running a slice when the predicted value from the leading thread does not match the predicted values. These methods all seek to add hardware to ensure that redundancy is achieved and to improve performance. For example, the Reinhardt / Mukherjee work (SRT) adds several queues to track values loaded and stored, and the Parashar work adds a bit matrix to track slices (in addition to the SRT hardware. TODO: This section can be expanded. Of note: The original Reinhardt and Mukherjee paper was followed by a decidedly less optimistic paper. The change in tone is summed up best by they authors: "We were certainly surprised that a seemingly straight-forward feature, added easily to our earlier SimpleScalar-based simulator, induced such complexities in this more realistic design." Sphere of ReplicationA useful tool from the Reinhardt work is the "Sphere of Replication": a demarcation of the hardware that is being provided replication through a particular technique, in this case a redundant thread. All inputs into the sphere must be duplicated; all outputs must be checked for consistency. All components not within the sphere will require their own fault detection mechanism if desired. Here we see two possible spheres, (b) is the one used for the Simultaneous and Redundantly Threaded processor. Software Only SolutionWork has been done with the Fiasco.OC kernel to provide for running redundant threads on commodity hardware without any hardware modifications. Main ref: Faults#Dobel12OSRedundant. Reliable Computing BaseOne idea advanced by the Döbel / Fiasco work is that of a Reliable Computing Base (RCB) in a similar sense as to the Trusted Computing Base found in security literature. It is the components of a system with must be assumed to be reliable in order to make reliability guarantees about all other parts of the system. The goal is to minimize the RCB as much as possible. ASTEROIDThis is the moniker for the entire Operating System used to demonstrate the ROMAIN system in the Döbel / Fiasco work. The components, in order from hardware to user applications, is as follows:
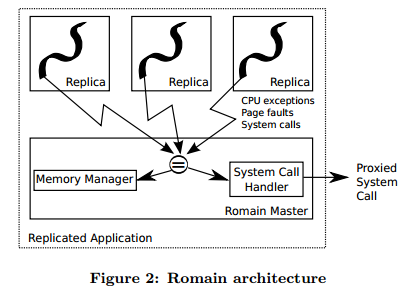
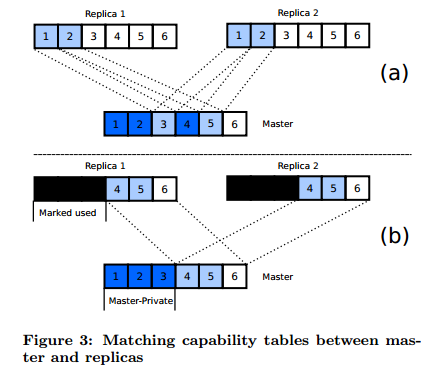
While the hardware shown above is potentially faulty, the team proposes using heterogeneous hardware in their Watchmen paper to secure the RCB. The hardware is a chip with a mix of regular cores and cores hardened against transient faults (which does not yet exist). The assumption is that the cores must be on the same chip as the paper states that inter-core communication speed is of great importance (this feature is apparently available on an experimental Intel chip, the Single Chip Cloud Computer). Section five of the paper elaborates on many possible hardware issues which mainly deal with how to interface between hardened cores and regular ones without exposing the system to new vulnerabilities. The suggestion of using specialized hardware for the RCB hearkens back to the work done by Reinhardt and Mukherjee, and begs the question: does transient fault protection require specialized hardware redundancy? Of particular interest may be whether or not the redundancy in COTS multicore chips could suffice for providing that protection (as mentioned at the end of one of the Reinhardt / Mukherjee papers. RomainA redundant threading library for Fiasco.OC which supports binary user applications. The Romain Master runs a N replicas of the user task (N depends on the reliability level desired), coordinates their inputs, and verifies their outputs. Execution of the replicas is only imposed upon when they attempt to externalize their state. For example, through making system calls or in the case of page faults. The Romain Master will then catch the call / exception, and wait for the other replicas to make the same call / exception (as they should if running properly). A watchdog timer is used to insure that they system does not wait indefinitely for a stalled replica. If a discrepancy is detected, Romain may be configured to recover in several ways. Voting may take place if enough replicas were run. Otherwise, the application can be restarted from a previous checkpoint. Source. Since Fiasco.OC is capability based, it stands to reason that capabilities must be handled in a special fashion to avoid heavy performance hits. However, the technique shown above may be a useful tool for any similar mapping. It eliminates a translation operation, which in a critical path can be significant. Performance Assumption: Benign FaultsMany software only approaches make the claim that a large number of SEUs are actually benign: they have no effect on the outcome of a program. The change of state (say a register that will not be read from) will be detected by hardware, triggering a recovery mechanism. However, since the SoR for a software approach matches the actual inputs and outputs of a software component, benign errors will not be detected. This reduces overheads by reducing how often the recovery mechanisms are enacted. See the Shye paper for evidence that many SEUs are in fact benign. Where do faults occur?From Operating System Support for Redundant Multithreading
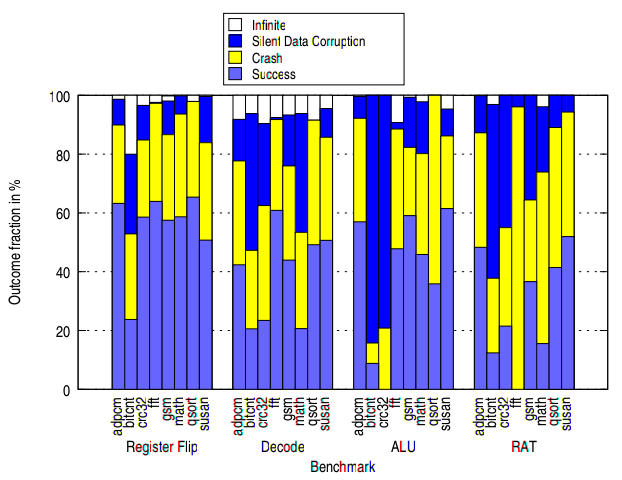 The RMT work itself found anywhere from 0% to 60% of errors masked, depending on the benchmark and the fault injected. The four faults shown in the image are (quoted from same paper, which cites [21] as the rational):
[2] Arlat, J., Fabre, J.-C., Society, I. C., Rodriguez, M., and Salles, F. Dependability of COTS microkernel-based systems. IEEE Transactions on Computers 51 (2002), 138–163. [21] Li, M.-L., Ramachandran, P., Sahoo, S. K., Adve, S. V., Adve, V. S., and Zhou, Y. Understanding the propagation of hard errors to software and implications for resilient system design. In Proceedings of the 13th International Conference on Architectural Support for Programming Languages and Operating Systems (New York, NY, USA, 2008), ASPLOS XIII, ACM, pp. 265–276. [36] Saggese, G. P., Wang, N. J., Kalbarczyk, Z. T., Patel, S. J., and Iyer, R. K. An experimental study of soft errors in microprocessors. IEEE Micro 25 (November 2005), 30–39. From PLR: A Software Approach to Transient Fault Tolerance for Multicore Architectures
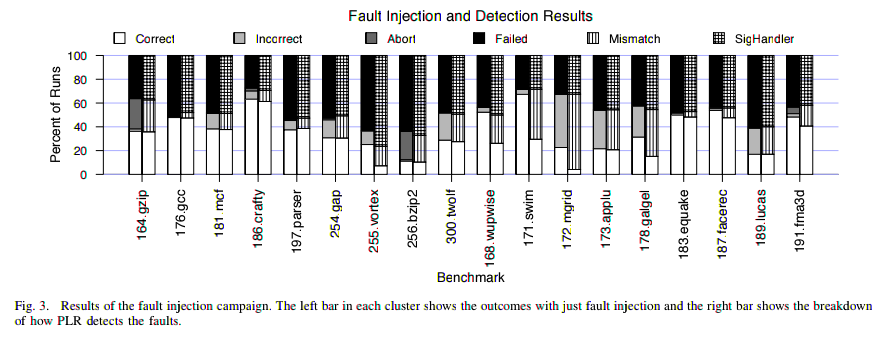
[15] N. J. Wang, J. Quek, T. M. Rafacz, and S. J. Patel, “Characterizing the effects of transient faults on a high-performance processor pipeline,” in Proceedings of the 2004 International Conference on Dependendable Systems and Networks, June 2004, pp. 61–72. Glossary / Acronyms
|