The mechanism for fault recovery depends upon system requirements as well as the fault Detection method employed. Some detection schemes do only that: detect a fault. In fact the system is expected to fail in this case (fail-stop is generally preferable to a silent failure that propagates errors to other components).
The type of fault also dictates the limits to the recovery mechanisms. In the case of Single Event Upsets (SEU or sometimes Transient Faults), which is our concern for now, re-computation or the operation or rebuilding of stored state is sufficient. How this is done is not necessarily straight forward.
Some common strategies are:
- Checkpointing - The state of the system is periodically verified. If an error is detected, the system is rolled back to the last correct checkpoint.
- Backtracking or Unwinding - When an error is detected, the program is basically run in reverse until the cause of the problem is detected then the program restarts from right before that point.
- Standby - A duplicate process is maintained and able to take over for a failed component.
- Cold-Standby - The duplicate is kept in a dormant state. Occasionally receives state updates. Must be started and catch up to the current system state upon a failure.
- Hot-Standby - The duplicate is executed as if it were the primary process with the exception that its outputs are ignored (or perhaps checked for consistency with the primary). Upon a failure, the duplicate can easily take over as it is already running and up to date (the last output may be buffered to ensure no outputs are lost).
- Voting (or Fault Masking) - Multiple (at least 3) instances of a component are executed. The outputs of these redundant components are checked against each other. If there is a discrepancy, an error has been detected. If a majority decision about the correct output can be reached, then no re-execution is needed; the most agreed upon value is used.
TODO: Tie into Redundant Multi-Threading(RMT).
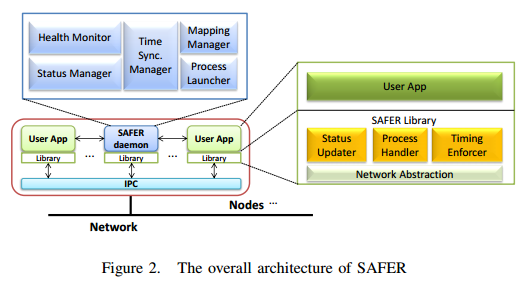
An Illustrative Example: SAFER
TODO: Complete this section.
TODO: Consider moving to System.
Glossary / Acronyms
- Fail-stop - A failure model in which a failure in a component is assumed to cause that component to immediately stop. In other words; failures do not propagate throughout the system or go unnoticed (perhaps in the form of corrupted data).