|
Research
Notes
Architecture
Faults
System
Planning
Background
OS
Misc
edit SideBar
|
These papers all have to do with recent work in fault detection and recovery.
SEU Source
Causal Relationships Between Solar Proton Events and Single Event Upsets for Communication Satellites
- Lohmeyer, Whitney Q and Cahoy, Kerri and Liu, Shiyang
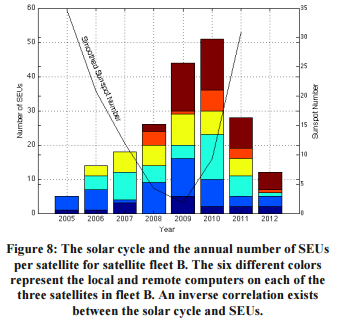
- Fairly light paper. Doesn't really say much. The interesting part is mostly that they have real data on SEUs from a fleet of communication satellites in geosynchronous orbit. Unfortunately (in a sense) the data is extremely limited: only 226 events over about a decade. Also, as far as I can tell, the data is not public and there is no telling what components experienced the SEU. Good for background and references to make the SEU case. They suggest that SEUs are most likely caused by galactic cosmic rays (which have an inverse relationship with the solar cycle) instead of direct effects from our sun such as solar particle events. The figure to the right is the most motivating result: SEUs year vs solar cycle.
One of the authors (Cahoy) has a set of slides related to the work: Attach:CahoySlides.pdf
- Attach:Lohmeyer13CausalSEU.pdf
@inproceedings{lohmeyer2013causal,
title={Causal relationships between solar proton events and single event upsets for communication satellites},
author={Lohmeyer, Whitney Q and Cahoy, Kerri and Liu, Shiyang},
booktitle={Aerospace Conference, 2013 IEEE},
pages={1--10},
year={2013},
organization={IEEE}
}
Terrestrial Cosmic Ray Intensities
- Ziegler, James F
- TODO: Read / Summarize
"Cosmic rays were first discovered because of the dogged curiosity of one man to explain a minor scientific irritation." - This is a wordy article, but interesting.
- Attach:ziegler1998terrestrial.pdf
@article{ziegler1998terrestrial,
title={Terrestrial cosmic ray intensities},
author={Ziegler, James F},
journal={IBM Journal of Research and Development},
volume={42},
number={1},
pages={117--140},
year={1998},
publisher={IBM}
}
Modeling the Effect of Technology Trends on the Soft Error Rate of Combinational Logic
@inproceedings{shivakumar02soft_errors,
title = {Modeling the Effect of Technology Trends on the Soft Error Rate of Combinational Logic},
author = {Shivakumar, Premkishore and Kistler, Michael and Keckler, Stephen W. and Burger, Doug and Alvisi, Lorenzo},
booktitle = {Proceedings of the 2002 International Conference on Dependable Systems and Networks},
series = {DSN '02},
year = {2002},
isbn = {0-7695-1597-5},
pages = {389--398},
numpages = {10},
url = {http://portal.acm.org/citation.cfm?id=647883.738394},
acmid = {738394},
publisher = {IEEE Computer Society},
address = {Washington, DC, USA},
}
Jiguo and Parmer's RTAS paper on C'MON has an appendix and a number of useful refs for this: SysPapers#Song15CMON
Taxonomy
A Robust Planning Framework for Cognitive Robots
- Karapinar, Sertac and Altan, Dogan and Sariel-Talay, Sanem
- Lackluster. Gedare recommended this paper for the taxonomy of robotic failures, but this taxonomy is not even used within the paper. Instead they divide failures into either "permanent" or "temporary." A "patience" (number of retries) property is used to distinquish between the two in the single experiment performed. And that experiment seems to just compare Bayes Network classification to Inductive Logic Programming (ILP).
- Attach:Karapinar12Framework.pdf
@inproceedings{karapinar2012robust,
title={A robust planning framework for cognitive robots},
author={Karapinar, Sertac and Altan, Dogan and Sariel-Talay, Sanem},
booktitle={Proceedings of the AAAI-12 Workshop on Cognitive Robotics (CogRob)},
year={2012}
}
A Survey of Fault-Tolerance and Fault-Recovery Techniques in Parallel Systems
- Treaster, Michael
- A light paper that covers typical fault models (Byzanine, Fail-stop, Fail-stutter), recovery techniques (hot / cold standby, check-pointing / rollback, logging), and some other potential issues. Targeted at parallel systems (clusters, HPC).
- Attach:Treaster05Survey.pdf
@article{treaster2005survey,
title={A survey of fault-tolerance and fault-recovery techniques in parallel systems},
author={Treaster, Michael},
journal={arXiv preprint cs/0501002},
year={2005}
}
Injection
A Software-Implemented Fault Injection Methodology for Design and Validation of System Fault Tolerance
- Some, Raphael R and Kim, Won S and Khanoyan, Garen and Callum, Leslie and Agrawal, Anil and Beahan, John J
- JPL's Implementation of a Fault Injector (JIFI) is a software based fault injection technique meant to simulate Single Event Upsets (SEUs). The application's source code is modified to call JIFI functions. Each "node" in the software forks a fault injector which then uses ptrace to inject the errors in both registers and memory. Designed for Linux as well as a real time version; LynxOS. Shows analysis of the approximately uniform distribution of faults injected. Had to do a bit of fiddling with scheduling (uses round robin scheduling).
- Attach:Some01JIFI.pdf
@inproceedings{some2001software,
title={A software-implemented fault injection methodology for design and validation of system fault tolerance},
author={Some, Raphael R and Kim, Won S and Khanoyan, Garen and Callum, Leslie and Agrawal, Anil and Beahan, John J},
booktitle={Dependable Systems and Networks, 2001. DSN 2001. International Conference on},
pages={501--506},
year={2001},
organization={IEEE}
}
FAIL*
Active research project for fault injection. First paper is why we need it, 2nd goes into more depth on how it works.
Avoiding Pitfalls in Fault-Injection Based Comparison of Program Susceptibility to Soft Errors
- Schirmeier, Horst and Borchert, Christoph and Spinczyk, Olaf
- Explains flaws in current literature dealing with how fault tolerance is measured. Gives the example of the "dilution" protection method which increases protection (with flawed metrics) by adding NOPs. Basically, the program's memory and processor footprint must be taken into account.
TODO: Finish summary
- Attach:Schirmeier2015Pitfalls.pdf
@inproceedings{schirmeier2015Pitfalls,
title={Avoiding pitfalls in fault-injection based comparison of program susceptibility to soft errors},
author={Schirmeier, Horst and Borchert, Christoph and Spinczyk, Olaf}
booktitle={Dependable Systems and Networks. DSN 2015. International Conference on},
year={2015},
organization={IEEE}
FAIL*: An Open and Versatile Fault-Injection Framework for the Assessment of Software-Implemented Hardware Fault Tolerance
- Schirmeier, Horst and Hoffmann, Martin and Dietrich, Christian and Lenz, Michael and Lohmann, Daniel and Spinczyk, Olaf
- Gives background on FAIL* and examples of research which has used it. A brief overview of the Fault Injection (Hardware, Software, and simulation based). FAIL* supports all three; in the demo configuration simulation based is used. Was used for the development of dosek. FAIL* shows where a program is vulnerable to bit-flips by tracing a golden run, then replaying with faults injected at each location (after pruning). May be of use to validate small sections of code, such as code paths in the voter, but unlikely to be able to answer questions about code making system calls and using libraries.
TODO: Dig into more details if necessary.
- Attach:Schirmeier2015FAIL.pdf
@inproceedings{schirmeier2015fail,
title={FAIL*: An open and versatile fault-injection framework for the assessment of software-implemented hardware fault tolerance},
author={Schirmeier, Horst and Hoffmann, Martin and Dietrich, Christian and Lenz, Michael and Lohmann, Daniel and Spinczyk, Olaf},
booktitle={Dependable Computing Conference (EDCC), 2015 Eleventh European},
pages={245--255},
year={2015},
organization={IEEE}
}
FPGA
Reconfigurable Fault Tolerant Avionics System
- Ibrahim, Mohamed Mahmoud and Asami, Kenichi and Cho, Mengu
- The idea is that a FPGA system can be configured with one processor during most of its orbit, and switch to a 3 proc configuration when in high radiation areas such as the South Atlantic Anomaly. The simulation is just of the orbit itself with some approximate (guessed) numbers for power consumption. Does calculate an error rate and reliability measurement, of which I am dubious. Pretty weak paper.
- Attach:Ibrahim13Reconfig.pdf
@inproceedings{ibrahim2013reconfigurable,
title={Reconfigurable fault tolerant avionics system},
author={Ibrahim, Mohamed Mahmoud and Asami, Kenichi and Cho, Mengu},
booktitle={Aerospace Conference, 2013 IEEE},
pages={1--12},
year={2013},
organization={IEEE}
}
Hardware Based
The RAD750 TM-a Radiation Hardened PowerPC TM Processor for High Performance Spaceborne Applications
- Berger, Richard W and Bayles, Devin and Brown, Ronald and Doyle, Scott and Kazemzadeh, Abbas and Knowles, Ken and Moser, D and Rodgers, J and Saari, B and Stanley, D and others.
- Description of the design process for the RAD750. Mostly over my head on the technical points. Of interest is that the processor is slow: high clock speeds and small parts make for a more vulnerable processor. It may not be possible to push rad-hardened much further. This is bolstered by the specs of the redesigned 2nd gen RAD750 10 years later: only 200MHz.
- Attach:Berger01RAD750.pdf
@inproceedings{berger2001rad750,
title={The RAD750 TM-a radiation hardened PowerPC TM processor for high performance spaceborne applications},
author={Berger, Richard W and Bayles, Devin and Brown, Ronald and Doyle, Scott and Kazemzadeh, Abbas and Knowles, Ken and Moser, D and Rodgers, J and Saari, B and Stanley, D and others},
booktitle={Aerospace Conference, 2001, IEEE Proceedings.},
volume={5},
pages={2263--2272},
year={2001},
organization={IEEE}
}
Second Generation (200MHz) RAD750 Microprocessor Radiation Evaluation
- Haddad, Nadim F and Brown, Ronald D and Ferguson, Richard and Kelly, Andrew T and Lawrence, Reed K and Pirkl, Daniel M and Rodgers, John C
- Short overview of the testing methodology for the 2nd gen RAD750. It can withstand more radiation, and increases from 240 to 400 mips. Average time between errors (SDCs) is 183 years for geosynchronous, which sounds pretty good.
- Attach:Haddad11SecondRAD750.pdf
@inproceedings{haddad2011second,
title={Second generation (200MHz) RAD750 microprocessor radiation evaluation},
author={Haddad, Nadim F and Brown, Ronald D and Ferguson, Richard and Kelly, Andrew T and Lawrence, Reed K and Pirkl, Daniel M and Rodgers, John C},
booktitle={Radiation and Its Effects on Components and Systems (RADECS), 2011 12th European Conference on},
pages={877--880},
year={2011},
organization={IEEE}
}
Transient Fault Detection via Simultaneous Multithreading
- Reinhardt, Steven K and Mukherjee, Shubhendu S
- Suggests (and justifies) modifications to be made to a SMT (Simultaneous MultiThreaded) processor to turn it into a SRT (Simultaneous and Redundantly Threaded) processor. The SRT duplicates a running thread to provide redundancy within a subsection of the hardware. All data into this subsection must be duplicated; all data out must be verified to be the same (otherwise a transient fault has occurred). Makes a convincing case that this is superior to duplicating all hardware and running a redundant thread in lockstep: hardware is shared increasing utilization and the redundant thread is allowed to "trail" the first (taking advantage of a warm cache and branch predictions).
The actual hardware added? "We use an ordered, non-coalescing store buffer shared between the redundant threads to synchronize and verify store values as they retire in program order from the RUU/LSQ." RUU - Register Update Unit, LSQ - Load Store Queue.
- Attach:Reinhardt00Simultaneous.pdf
@inproceedings{reinhardt2000transient,
title={Transient fault detection via simultaneous multithreading},
author={Reinhardt, Steven K and Mukherjee, Shubhendu S},
booktitle={ACM SIGARCH Computer Architecture News},
volume={28},
number={2},
pages={25--36},
year={2000},
organization={ACM}
}
Detailed Design and Evaluation of Redundant Multithreading Alternatives
- Mukherjee, Shubhendu S and Kontz, Michael and Reinhardt, Steven K
- A continuation of the work above; this paper refers to the previous work as overly optimistic, a result of a simplistic model of SMT processors. However, improvements over lock-stepping were shown in additional to adding detection for some permanent faults by forcing threads to utilize different existing hardware components. Section 5 discusses multi-core multithreaded applications, but I have my reservations about their assumptions about the cost of core to core communication. It would be interesting to see how this work stands up today with the proliferation of SMT processors.
- Attach:Mukherjee02Detailed.pdf
@inproceedings{mukherjee2002detailed,
title={Detailed design and evaluation of redundant multi-threading alternatives},
author={Mukherjee, Shubhendu S and Kontz, Michael and Reinhardt, Steven K},
booktitle={Computer Architecture, 2002. Proceedings. 29th Annual International Symposium on},
pages={99--110},
year={2002},
organization={IEEE}
}
SlicK: Slice-Based Locality Exploitation for Efficient Redundant Multithreading
- Parashar, Angshuman and Gurumurthi, Sudhanva and Sivasubramaniam, Anand
- Introduces using Slices of computation (seem to be groupings of instructions that contribute to an output (store)) as the base unit for redundancy. Depends upon being able to predict the output for a particular slice (of which I am dubious... should check references). The lead thread runs the slice, and if the output is as predicted, then the trailing thread does not verify. Does not offer 100% protection as tested, but instead offers a trade off between performance vs coverage (although vulnerabilities seem low).
- Attach:Parashar2006SlicK.pdf
@inproceedings{parashar2006slick,
title={SlicK: Slice-Based Locality Exploitation for Efficient Redundant Multithreading},
author={Parashar, Angshuman and Gurumurthi, Sudhanva and Sivasubramaniam, Anand},
booktitle={International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS). Proceedings},
volume={40},
number={5},
pages={95--105},
year={2006},
}
SAFER: System-level Architecture for Failure Evasion in Real-time Applications
- Kim, Junsung and Bhatia, Gaurav and Rajkumar, Ragunathan Raj and Jochim, Markus
- Using Boss (CMU's entry into DARPA's urban vehicle challenge) as a testbed, SAFER provides robust failure recovery by applying well understood techniques such as Hot Standby in the context of a real-time system. The cost is significant: triplicate hardware in some cases, but being able to recover from faults within a defined deadline is the payoff. Faults are assumed to be fail-stop, but this can be relaxed if voting is enabled (can easily protect against most non-fail-stop errors). Also provides for some flexibility in protection level / deadlines, such as cold standbys and few replicated processes.
- Attach:Kim12SAFER.pdf
@inproceedings{kim2012safer,
title={SAFER: System-level Architecture for Failure Evasion in Real-time Applications},
author={Kim, Junsung and Bhatia, Gaurav and Rajkumar, Ragunathan Raj and Jochim, Markus},
booktitle={Real-Time Systems Symposium (RTSS), 2012 IEEE 33rd},
pages={227--236},
year={2012},
organization={IEEE}
}
Formal Specification and Mechanical Verification of SIFT: A Fault-Tolerant Flight Control System
- Melliar-Smith, P Michael and Schwartz, Richard L
- Uses multiple processors and software voting (so redundant, but not specialized hardware is used) for an avionics system. Has a hierarchy of requirements. Each processor (up to 8, Bendix BDX930) has a data file which has a slot for every processor to deliver data (its own is an output buffer), and data is broadcast to all other processors. Each task is replicated 3 or 5 times. The next task in the pipeline just reads from those 3 (or 5) input buffers.
"Thus, validation by fault injection, while necessary, is unlikely to convince us that SIFT meets its reliability requirements."
TODO: Finish summary
- Attach:MelliarSmith1982SIFT.pdf Δ
@article{melliar1982formal,
title={Formal specification and mechanical verification of SIFT: A fault-tolerant flight control system},
author={Melliar-Smith, P Michael and Schwartz, Richard L},
journal={Computers, IEEE Transactions on},
volume={100},
number={7},
pages={616--630},
year={1982},
publisher={IEEE}
}
Hybrid Methods
There isn't always a clear distinction, as many of the software methods may suggest slight hardware modifications and vice versa. I am also using this section for systems that combine hardware and software methods.
Hardware-Software Integrated Diagnosis for Intermittent Hardware Faults
- Dadashi, M. and Rashid, L. and Pattabiraman, K. and Gopalakrishnan, S.
- Concerned with Intermittent faults, not transient. Useful for references and background knowledge. Presents a set of hardware modifications which record resource usage of instructions, and a software component which can use this to "diagnose" faults by replaying the code and seeing were resource use diverges. Makes some big assumptions, such as the faults all being detected (usually through a system fault). Did not fully read.
- Attach:Dadashi14Intermittent.pdf
@INPROCEEDINGS{dadashi14intermittent,
author={Dadashi, M. and Rashid, L. and Pattabiraman, K. and Gopalakrishnan, S.},
booktitle={Dependable Systems and Networks (DSN), 2014 44th Annual IEEE/IFIP International Conference on},
title={Hardware-Software Integrated Diagnosis for Intermittent Hardware Faults},
year={2014},
month={June},
pages={363-374},
doi={10.1109/DSN.2014.1}
}
GUARDS: A Generic Upgradable Architecture for Real-Time Dependable Systems
- Powell, David and Arlat, Jean and Beus-Dukic, Ljerka and Bondavalli, Andrea and Coppola, Paolo and Fantechi, Alessandro and Jenn, Eric and Rab{\'e}jac, Christophe and Wellings, Andrew
- A long (17 page) work describing the 3-axis (channel, lane and integrity) of fault protection afforded by GUARDS: a generic architecture for building robust networks / systems out of COTS parts (hardware and software). Section 5 seems to be of particular interest, discussing "interchannel" redundancy, but lacks implementation details. 8.3 briefly discusses fault injection. Section 9 has several examples, which help deliniate the 3-axis they have identified.
The paper is broad in scope, covering verification and the network requirements. Specific papers on the components I am interested in are worth reviewing.
- Attach:Powell1999GUARDS.pdf
@article{powell1999guards,
title={GUARDS: A generic upgradable architecture for real-time dependable systems},
author={Powell, David and Arlat, Jean and Beus-Dukic, Ljerka and Bondavalli, Andrea and Coppola, Paolo and Fantechi, Alessandro and Jenn, Eric and Rab{\'e}jac, Christophe and Wellings, Andrew},
journal={Parallel and Distributed Systems, IEEE Transactions on},
volume={10},
number={6},
pages={580--599},
year={1999},
publisher={IEEE}
}
Software Based: Code
NB: Steven S. mentioned that some medical applications use language annotations to denote critical variables, which the compiler would then duplicate and insert checks for. Not sure if it is worth digging into, but that would go here if I did.
Reliable Software for Unreliable Hardware: Embedded Code Generation Aiming at Reliability
@inproceedings{rehman2011reliable,
title={Reliable software for unreliable hardware: embedded code generation aiming at reliability},
author={Rehman, Semeen and Shafique, Muhammad and Kriebel, Florian and Henkel, J{\"o}rg},
booktitle={Proceedings of the seventh IEEE/ACM/IFIP international conference on Hardware/software codesign and system synthesis},
pages={237--246},
year={2011},
organization={ACM}
}
A New Software-Based Technique for Low-Cost Fault-Tolerant Application
- Rebaudengo, Maurizio and Reorda, M Sonza and Violante, Massimo
- A short (3 page) work demonstrating protecting data from transient errors at an instuction level (in C I think) by duplicating all variables and maintaining a checksum for one set of variables. At each read, a new checksum is calculated and compared to the old. Based on benchmark programs with faults injected (weighted by increase in data segment size), the system protects against upwards of 99.5% of the errors.
In relation to my work: why use this (or other instruction level techniques) instead of NMR? Could this, in conjunction with the control flow protection methods cited, be used to protect the Voter?
- Attach:Rebaudengo2003NewIL.pdf
@inproceedings{rebaudengo2003new,
title={A new software-based technique for low-cost fault-tolerant application},
author={Rebaudengo, Maurizio and Reorda, M Sonza and Violante, Massimo},
booktitle={Reliability and Maintainability Symposium, 2003. Annual},
pages={25--28},
year={2003},
organization={IEEE}
}
SWIFT: Software Implemented Fault Tolerance
- Reis, George A and Chang, Jonathan and Vachharajani, Neil and Rangan, Ram and August, David I
- Modifies the assembly code of a program to provide software protection. For example,
load instructions are duplicated, and store instructions are replaced with comparisons. The logic becomes more complicated for protecting code branches. Only duplicates code once (although they mention TMR is possible, it is not evaluated), but is able to (for the most part) achieve better performance results than simply 2x the old speed (code size does balloon, however). This is attributed to compiler optimizations. I was a bit surprised, as I thought register contention would be a problem (but it may still be on x86, especially in the case of TMR) Uses the IA-64 (Itanium) instruction set, which has 128 integer and 128 floating registers. I am fairly certain that performance would be horrible on a register constrained architecture. The fault injection results are interesting. All SDC cases are caught. The number of correct runs, with fault detection, is much less than without. This is attributed to most faults not actually changing program output, the larger code-base of the protected code (thus more faults injected), and the fact that the framework is using double redundancy, and thus can only detect faults, not necessarily recover from them.
- Attach:Reis05SWIFT.pdf
@inproceedings{reis2005swift,
title={SWIFT: Software implemented fault tolerance},
author={Reis, George A and Chang, Jonathan and Vachharajani, Neil and Rangan, Ram and August, David I},
booktitle={Proceedings of the international symposium on Code generation and optimization},
pages={243--254},
year={2005},
organization={IEEE Computer Society}
}
Software Based: Process
Using Process-Level Redundancy to Exploit Multiple Cores for Transient Fault Tolerance
- Shye, Alex and Moseley, Tipp and Reddi, Vijay Janapa and Blomstedt, Joseph and Connors, Daniel A
- (Journal paper below) Introduces Process-Level Redundancy and show decent performance assuming a multi-core processor (thus allowing each replicated process to run on its own core). Limited to single threaded applications, and does not cover the operating system. Lays out the case for a software-centric view of redundancy verses hardware-centric. System call emulation is the main mechanism for checking consistency.
Results also show that a large number of faults (in there model which likely underestimates) are in fact benign. Background section has a useful breakdown of faults be their effect on the system (benign, silent corruption, unrecoverable).
- Attach:Shye07ProcessRedundancy.pdf
@inproceedings{shye2007using,
title={Using process-level redundancy to exploit multiple cores for transient fault tolerance},
author={Shye, Alex and Moseley, Tipp and Reddi, Vijay Janapa and Blomstedt, Joseph and Connors, Daniel A},
booktitle={Dependable Systems and Networks, 2007. DSN'07. 37th Annual IEEE/IFIP International Conference on},
pages={297--306},
year={2007},
organization={IEEE}
}
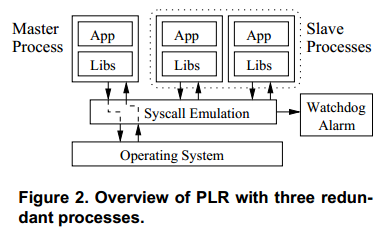
PLR: A Software Approach to Transient Fault Tolerance for Multicore Architectures
- Shye, Alex and Blomstedt, Joseph and Moseley, Tipp and Reddi, Vijay Janapa and Connors, Daniel A
- The journal version of the work above, printed one year later. Great source of references and lays out the background and problem well. A single process is split into three replica processes and a figurehead process (to deal with annoying bits like not being able to catch sigterms). TODO: Finish summary.
Suggests using
fork to recover processes, but does not implement.
Fig. 3 shows fault injection results; depending on the program, ~10% to ~65% of the injected faults (using Intel Pin) are ultimately benign.
- Attach:Shye09PLR.pdf
@article{shye2009plr,
title={PLR: A software approach to transient fault tolerance for multicore architectures},
author={Shye, Alex and Blomstedt, Joseph and Moseley, Tipp and Reddi, Vijay Janapa and Connors, Daniel A},
journal={Dependable and Secure Computing, IEEE Transactions on},
volume={6},
number={2},
pages={135--148},
year={2009},
publisher={IEEE}
}
Software-Based Fault tolerance for the Maestro Many-Core Processor
- Walters, John Paul and Kost, Robert and Singh, Karandeep and Suh, Jinwoo and Crago, Stephen P
- Maestro is based on the TILE64 processor, and has a 7x7 mesh of processor "tiles." This work details four software strategies for dealing with transient faults. 1) Process level redundancy (PLR... link to shye?): runs three processes each on their own tile, started by interposing on the
open system call with voting done when the file is closed. 2) Thread level redundancy: a library for running a function in triplicate using threads. 3) Heartbeats: used to detect when tiles become unresponsive, did not read in detail. 4) Checkpoint / Restart: uses a port of Linux-CR (link?) v15.
- Attach:Walters2011Maestro.pdf
@inproceedings{walters2011software,
title={Software-based fault tolerance for the Maestro many-core processor},
author={Walters, John Paul and Kost, Robert and Singh, Karandeep and Suh, Jinwoo and Crago, Stephen P},
booktitle={Aerospace Conference, 2011 IEEE},
pages={1--12},
year={2011},
organization={IEEE}
}
Software Based: OS
Also look under SysPapers#Composite
CuriOS: Improving Reliability Through Operating System Structure
- David, Francis M and Chan, Ellick M and Carlyle, Jeffrey C and Campbell, Roy H
- Similar to the Minix work, which they mention, this work is more focused on kernel errors in general. It does mention the possible application of transient fault protection (through voting or other mechanisms), but in the context of being applicable. They do inject random bit-flips, to which the system recovers in the large majority of cases, but there is no provision against SDC.
- Attach:David2008CuriOS.pdf
@inproceedings{david2008curios,
title={CuriOS: improving reliability through operating system structure},
author={David, Francis M and Chan, Ellick M and Carlyle, Jeffrey C and Campbell, Roy H},
booktitle={Proceedings of the 8th USENIX conference on Operating systems design and implementation},
pages={59--72},
year={2008},
organization={USENIX Association}
}
Operating System Support for Redundant Multithreading
- Döbel, Björn and Härtig, Hermann and Engel, Michael
- A software only approach with has been implemented in Fiasco.OC called Romain, which uses transparent (to the user level) redundant threads. Introduces the concept of the Reliable Computing Base (RCB, similar in concept to the Trusted Computing Base of security work). Surprisingly good results are reported (30% worse case overhead, 5% common for triple modular redundancy (each replica and master with a dedicated core)). Errors are checked for only at system calls and exceptions, which takes advantage of their assumption that the majority of SEUs do not actually impact program outcome.
- Attach:Dobel12OSRedundant.pdf
@inproceedings{dobel2012operating,
title={Operating system support for redundant multithreading},
author={D{\"o}bel, Bj{\"o}rn and H{\"a}rtig, Hermann and Engel, Michael},
booktitle={Proceedings of the tenth ACM international conference on Embedded software},
pages={83--92},
year={2012},
organization={ACM}
}
Who Watches the Watchmen? Protecting Operating System Reliability Mechanisms
- Döbel, Björn and Härtig, Hermann
- The basic premise: the Reliable Computing Base of ASTEROID (discussed above) can be protected via hardware which protects against transient faults. This leads to a heterogeneous system with reliable and unreliable cores. This hardware does not yet exist. The assumption seems to be that the cores are all on the same chip, at least from the stated requirement of high speed inter-core communication (with Message Passing Buffers as a solution, despite it being available thus far only on an experimental Intel chip, the Single Chip Cloud Computer). Section 5 discusses hardware requirements; specifically the difficulty in defining the interface between the reliable cores and the non-reliable ones in such a way that new vulnerabilities are not created.
- Attach:Dobel12Watchmen.pdf
@inproceedings{dobel2012watches,
title={Who watches the watchmen? protecting operating system reliability mechanisms},
author={D{\"o}bel, Bj{\"o}rn and H{\"a}rtig, Hermann},
booktitle={8th Workshop on Hot Topics in System Dependability (HotDep’12). Available at https://www. usenix. org/system/files/conference/hotdep12/hotdep12-final1. pdf},
year={2012}
}
Distributed Real-Time Fault Tolerance on a Virtualized Multi-Core System
- Missimer, Eric and West, Richard and Li, Ye
- OSPERT14 workshop paper on Quest-V: a chip-level distributed system for providing fault tolerance. The cores of the chip are partitioned, and a hypervisor of sorts checks for consistency between cores. While TMR can be provided, output voting is not the means to check consistency. Instead, when a sandboxed program reaches a synchronization point (such as a system call or VM exit), the entire sandboxes memory is hashed.
This work is similar to Mukherjee's above in that it exploits multicore processors. Missimer does not add any hardware, and consistency is checked on memory, not computational outputs.
TODO: Look into Attach:li2014virtualized.pdf and / or Attach:li2014predictable.pdf
- Attach:missimer2014distributed.pdf
@article{missimer2014distributed,
title={Distributed Real-Time Fault Tolerance on a Virtualized Multi-Core System},
author={Missimer, Eric and West, Richard and Li, Ye},
journal={OSPERT 2014},
pages={17},
year={2014}
}
dOSEK: the Design and Implementation of a Dependability-Oriented Static Embedded Kernel
- Hoffmann, Martin and Lukas, Florian and Dietrich, Christian and Lohmann, Daniel
- Introduces dOSEK, an OSEK compliant RTOS that seeks to provide the much sought after RCB. Goal is to provide fault detection and containment for SEUs (mostly SDCs). A lot of this is accomplished statically by reducing the amount of live state in the kernel (since ROM is assumed to be safe). System calls are inlined to avoid stack pointer / return address problems. Loops are unrolled to prevent control flow errors. ANB encoding is also used... need to look into.
Validating by simulating a quadcopter control program, and used a hardware simulator along with the FAIL* framework to inject faults.
dOSEK Research Site
- Attach:Hoffmann2015dOSEK.pdf
@inproceedings{hoffmann2015dosek,
title={dOSEK: the design and implementation of a dependability-oriented static embedded kernel},
author={Hoffmann, Martin and Lukas, Florian and Dietrich, Christian and Lohmann, Daniel},
booktitle={Real-Time and Embedded Technology and Applications Symposium (RTAS), 2015 IEEE},
pages={259--270},
year={2015},
organization={IEEE}
}
Middleware
Reliable Distributed Real-Time and Embedded Systems through Safe Middleware Adaptation.
- Dabholkar, Akshay and Dubey, Abhishek and Gokhale, Aniruddha S and Karsai, Gabor and Mahadevan, Nagabhushan
- For "systems of systems" - SafeMAT (Safe Middleware Adaptation for Real-Time Fault Tolerance) runs on top of an existing network of real time embedded systems (ARINC 653 based). Measures the slack available, which is used to provide fail-over for partitions (processes) by moving them to an available module (processor). TODO: Finish reading / summary
- Attach:dabholkar2012reliable.pdf
@inproceedings{dabholkar2012reliable,
title={Reliable Distributed Real-Time and Embedded Systems through Safe Middleware Adaptation.},
author={Dabholkar, Akshay and Dubey, Abhishek and Gokhale, Aniruddha S and Karsai, Gabor and Mahadevan, Nagabhushan},
booktitle={SRDS},
pages={362--371},
year={2012}
}
Adaptive Failover for Real-Time Middleware with Passive Replication
- Balasubramanian, Jaiganesh and Tambe, Sumant and Lu, Chenyang and Gokhale, Aniruddha and Gill, Christopher and Schmidt, Douglas C
- Introduces FLARe (Fault-tolerant Load-aware and Adaptive middlewaRe), which does dynamic load balancing for distributed soft real-time systems built on Real-time CORBA. Specifically focuses on making passive replication as predictable as active, but without the associated overheads. Failure model assumes fail-stop. The load balancing might be interesting.
- Attach:balasubramanian2009adaptive.pdf
@inproceedings{balasubramanian2009adaptive,
title={Adaptive failover for real-time middleware with passive replication},
author={Balasubramanian, Jaiganesh and Tambe, Sumant and Lu, Chenyang and Gokhale, Aniruddha and Gill, Christopher and Schmidt, Douglas C},
booktitle={Real-Time and Embedded Technology and Applications Symposium, 2009. RTAS 2009. 15th IEEE},
pages={118--127},
year={2009},
organization={IEEE}
}
A Framework-Based Approach for Fault-Tolerant Service Robots
- Ahn, Heejune and Loh, Woong-Kee and Yeo, Woon-Young
- Presents OPRoS, a component based framework which provides for fault tolerance. TODO: Finish.
- Attach:Ahn12FrameworkOPRoS.pdf
@article{ahn2012framework,
title={A Framework-Based Approach for Fault-Tolerant Service Robots.},
author={Ahn, Heejune and Loh, Woong-Kee and Yeo, Woon-Young},
journal={International Journal of Advanced Robotic Systems},
volume={9},
year={2012}
}
PAXOS
Paxos for System Builders: an Overview
@inproceedings{kirsch2008paxos,
title={Paxos for system builders: an overview},
author={Kirsch, Jonathan and Amir, Yair},
booktitle={Proceedings of the 2nd Workshop on Large-Scale Distributed Systems and Middleware},
pages={3},
year={2008},
organization={ACM}
}
HardPaxos: Replication Hardened against Hardware Errors
@INPROCEEDINGS{6983398,
title={HardPaxos: Replication Hardened against Hardware Errors},
author={Behrens, D. and Kuvaiskii, D. and Fetzer, C.},
booktitle={Reliable Distributed Systems (SRDS), 2014 IEEE 33rd International Symposium on},
year={2014},
month={Oct},
pages={232-241},
keywords={fault tolerant computing;AN-encoding;HardPaxos;SMR systems;atomic broadcast algorithm;duplicated execution;fault injection;replication hardened against hardware errors;state machine replication;state overhead;Computer crashes;Hardware;Law;Libraries;Proposals;Radiation detectors;Byzantine faults;Paxos;hardware errors},
doi={10.1109/SRDS.2014.13},}
Grid Computing
While the conditions are different from that of robotics, the field has a mature background in distributed computation.
Smart Redundancy for Distributed Computation
- Brun, Yuriy and Edwards, George and Bang, Jae Young and Medvidovic, Nenad
- The two improvements upon traditional (k-modular) redundancy are fairly obvious: only run enough duplicates to gain a consensus, run more as needed if some disagree. But, the evaluation is solid. Provides a good summary of the techniques.
- Attach:Brun11ProgressiveRedundancy.pdf
@inproceedings{brun2011smart,
title={Smart redundancy for distributed computation},
author={Brun, Yuriy and Edwards, George and Bang, Jae Young and Medvidovic, Nenad},
booktitle={Distributed Computing Systems (ICDCS), 2011 31st International Conference on},
pages={665--676},
year={2011},
organization={IEEE}
}
Replication-Based Fault-Tolerance for Large-Scale Graph Processing
- Peng Wang and Kaiyuan Zhang and Rong Chen and Haibo Chen and Haibing Guan
- Not sure about this one, and the terminology is different than what I am used to. Probably because it deals with graph parallel processing. Apparently, a common optimization in the field is to have state replicas on different machines to reduce network communication. This paper leverages that to allow for fault-tolerance. New replicas only need to be added for masters lacking mirrors. Discusses some recovery strategies. Compares to a check-pointing scheme, but I don't know if the results are fair. Do not want to dig too deep since not directly related.
- Attach:Wang14ReplicationGraph.pdf
@INPROCEEDINGS{Wang14ReplicationGraph,
author={Peng Wang and Kaiyuan Zhang and Rong Chen and Haibo Chen and Haibing Guan},
booktitle={Dependable Systems and Networks (DSN), 2014 44th Annual IEEE/IFIP International Conference on},
title={Replication-Based Fault-Tolerance for Large-Scale Graph Processing},
year={2014},
month={June},
pages={562-573},
doi={10.1109/DSN.2014.58}}
|